Abstract
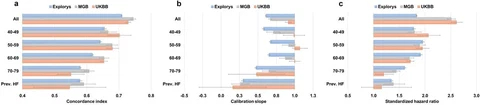
Prediction models are commonly used to estimate risk for cardiovascular diseases, to inform diagnosis and management. However, performance may vary substantially across relevant subgroups of the population. Here we investigated heterogeneity of accuracy and fairness metrics across a variety of subgroups for risk prediction of two common diseases: atrial fibrillation (AF) and atherosclerotic cardiovascular disease (ASCVD). We calculated the Cohorts for Heart and Aging in Genomic Epidemiology Atrial Fibrillation (CHARGE-AF) score for AF and the Pooled Cohort Equations (PCE) score for ASCVD in three large datasets: Explorys Life Sciences Dataset (Explorys, n=21,809,334), Mass General Brigham (MGB, n=520,868), and the UK Biobank (UKBB, n=502,521). Our results demonstrate important performance heterogeneity across subpopulations defined by age, sex, and presence of preexisting disease, with fairly consistent patterns across both scores. For example, using CHARGE-AF, discrimination declined with increasing age, with a concordance index of 0.72 [95% CI 0.72–0.73] for the youngest (45–54 years) subgroup to 0.57 [0.56–0.58] for the oldest (85–90 years) subgroup in Explorys. Even though sex is not included in CHARGE-AF, the statistical parity difference (i.e., likelihood of being classified as high risk) was considerable between males and females within the 65–74 years subgroup with a value of −0.33 [95% CI −0.33 to −0.33]. We also observed weak discrimination (i.e., <0.7) and suboptimal calibration (i.e., calibration slope outside of 0.7–1.3) in large subsets of the population; for example, all individuals aged 75 years or older in Explorys (17.4%). Our findings highlight the need to characterize and quantify the behavior of clinical risk models within specific subpopulations so they can be used appropriately to facilitate more accurate, consistent, and equitable assessment of disease risk.